GraphQL An Alternative To Your API
GraphQL an alternative to your API
Today I will talk about graphql, early we begin in the content in-depth, let’s remember important things about the distributed systems.

source: https://www.mypassionfor.net/2020/03/11/8-fallacies-of-distributed-computing/
The image above shows for us the fallacies about distributed systems, for now, we have attention to latency is zero, bandwidth is infinite and transport costs is zero. This is more visible to APIs because it affects the client experience of your applications.
The GraphQL
GraphQL is a query language and server runtime to build and expose an API. Today graphQL is an alternative to REST, where the main characteristic is that the tools are centralized on the data where the client wants and your fields into an endpoint. Even so, the REST runs on top of the HTTP. The image below shows us what a graph is. Nodes and edges with relationships that have attributes.
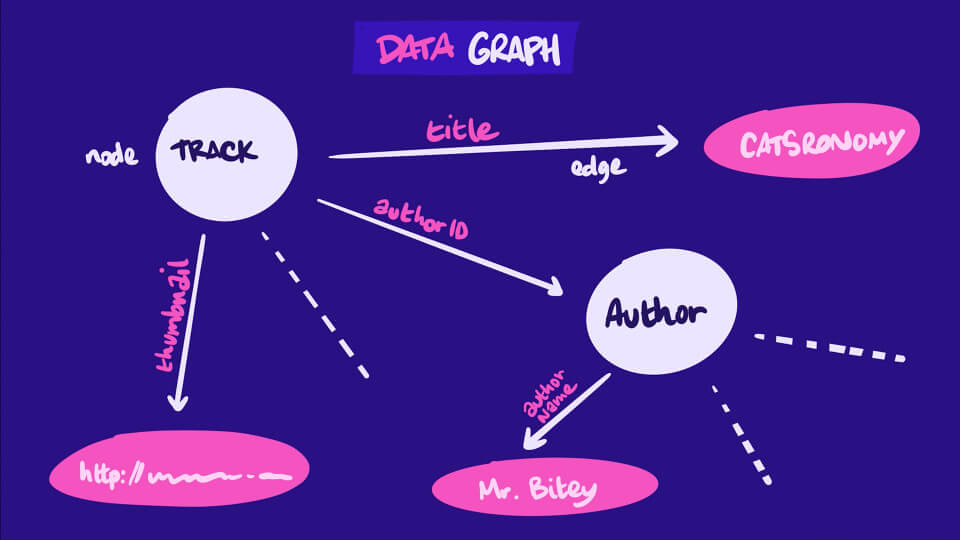
source: https://odyssey.apollographql.com/lift-off-part1/feature-data-requirements
GraphQL was created by Facebook in 2012 and later turned into an open-source project. Facebook developed the tool for the native mobile application that needs to have made a bit request to the backend to improve the experience of the users. The tool is based on queries and mutations. Where queries are the read operations over data and mutations are the update, delete and create operations. GraphQL is built around a type system that is statically typed.
The Schema
The schema is the definition of the API, based on scalar type (Int, Float, String, Boolean, ID), enums, or complex types.
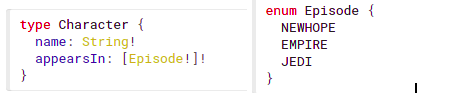
source: https://graphql.org/learn/schema/
The above image shows for us the type Character with scalar type String and called name and another field named appearsIn with the enum type Episode. In this example, the Character is a complex type if it is used in another type.
Queries and Mutations
The query is the way if we get the data from the API. In the above example, we could see a query called a hero and we want to get the name of it.

source: https://graphql.org/learn/schema/
However, for this query to work, we need to create a file with the definitions of the API with types, queries, and mutations.

source: https://graphql.org/learn/schema/
We need to implement it in a function called resolver that extends some resolver interface of your technology that is responsible for retrieving the data from the data source that can be a data store, file, or a REST API.
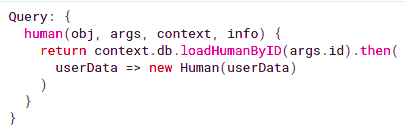
source: https://graphql.org/learn/schema/
Mutation maintains the same approach.
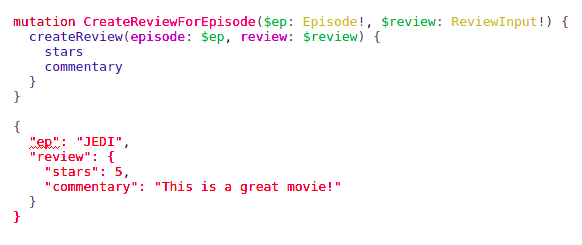
source: https://graphql.org/learn/schema/
The graphQL is in the same place that other technology like RPC or REST, your business logic keep in the same place.
source: https://graphql.org/learn/schema/
Queries types
We can use arguments on the queries like this:

source: https://graphql.org/learn/schema/
We can use an alias on the queries too:
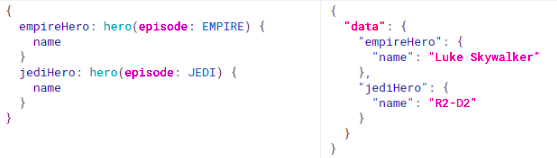
source: https://graphql.org/learn/schema/
There is a lot of functionality to make queries in GraphQl. You can create interfaces, combine types, and so on.
Subscriptions
Besides queries and mutations, graphql provides another operation type called subscription. This allows us to have real-time changes on the client-side. Subscriptions run on top of the WebSocket, so it established a full-duplex connection between the client and server.
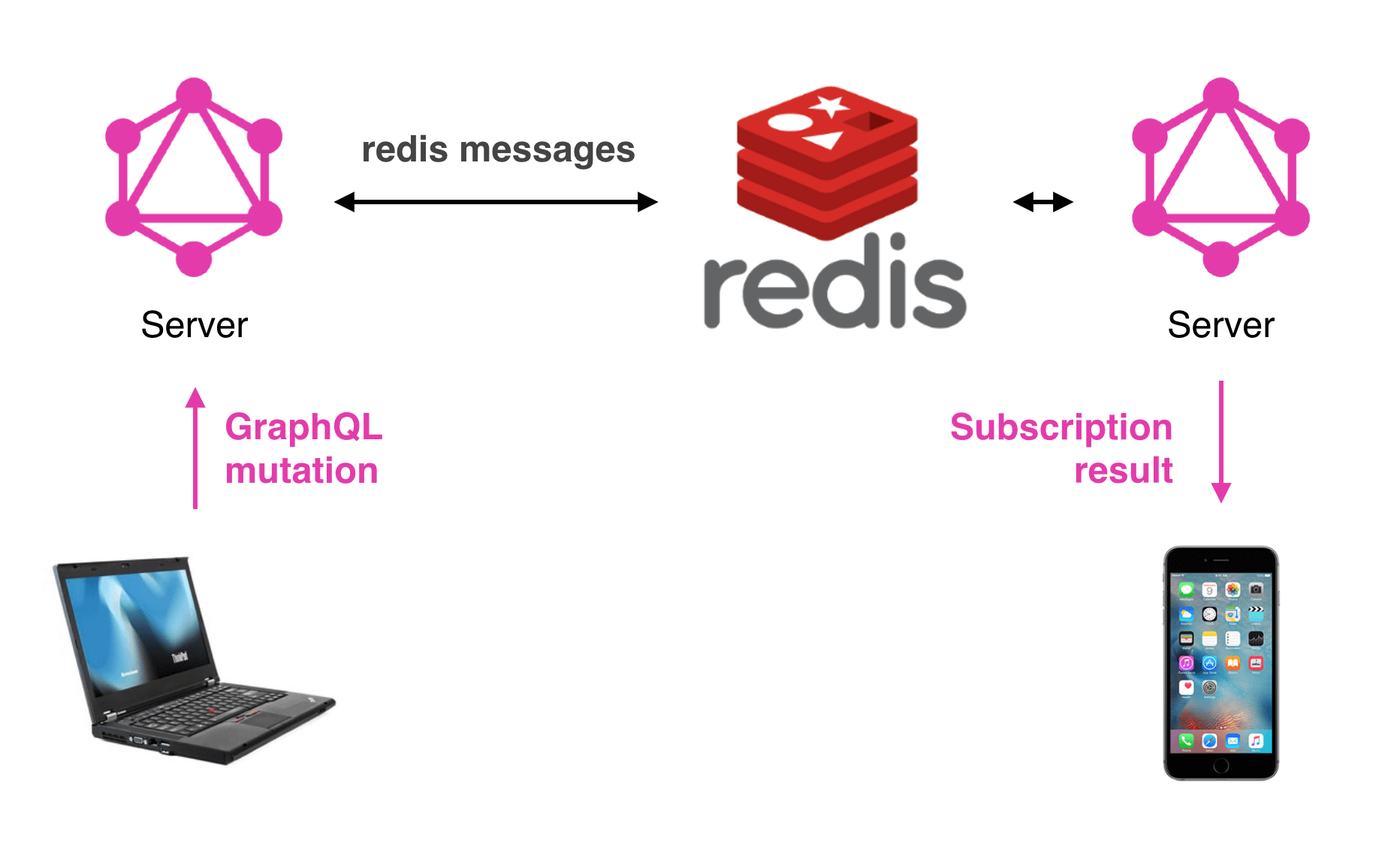
source: https://www.apollographql.com/blog/graphql-subscriptions-with-redis-pub-sub-f636fc84a0c4/
In the above image, we see this implementation using the Redis like a queue to provide the reactive events.
First, we need to create a special type in the schema, subscription:
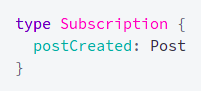
source: https://www.apollographql.com/docs/apollo-server/data/subscriptions/
Second, the subscription on the client-side, configure the WebSocket URL, and the query to stay listen to the events from the server:
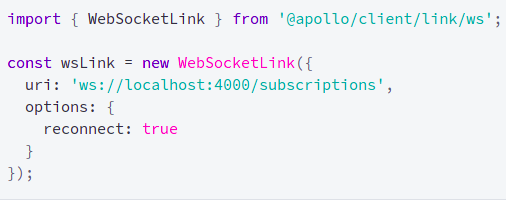
source: https://www.apollographql.com/docs/react/data/subscriptions/

source: https://www.apollographql.com/docs/react/data/subscriptions/
Third, on the server side we create another endpoint called /subscriptions to trait these events:
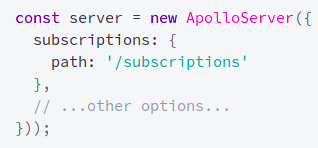
source: https://www.apollographql.com/docs/react/data/subscriptions/
And last, the event listener to hear this event and then dispatch the change to the client.
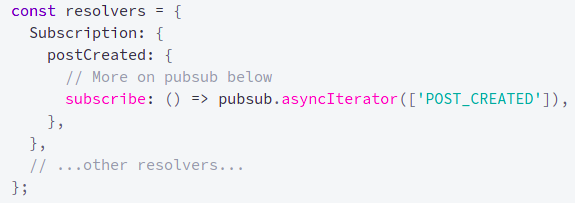
source: https://www.apollographql.com/docs/react/data/subscriptions/
Where the pubsub is the interface that implements a pub/sub or queue, like Redis, Kafka, RabbitMQ, Google Pub/Sub, and so on. So when the POST_CREATED is published into the pub/sub or queue, this subscriber notifies the subscriptions that use WebSocket with already connection established and the client could trait this data how they want.
REST x GraphQL
The most visible difference between a REST API and GraphQL is that one uses multiple endpoints to return data to the client, and the other uses a simple endpoint.
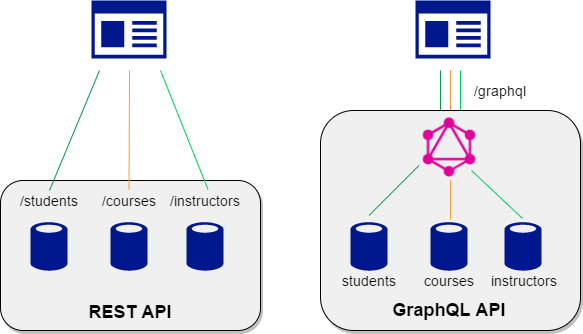
source: https://bagisto.com/en/top-5-key-features-of-multichannel-ecommerce/
Another thing to consider is the over and under fetching, for instance, if we have an endpoint that returns the data about the films, in the REST we go to receive all fields in the endpoint.
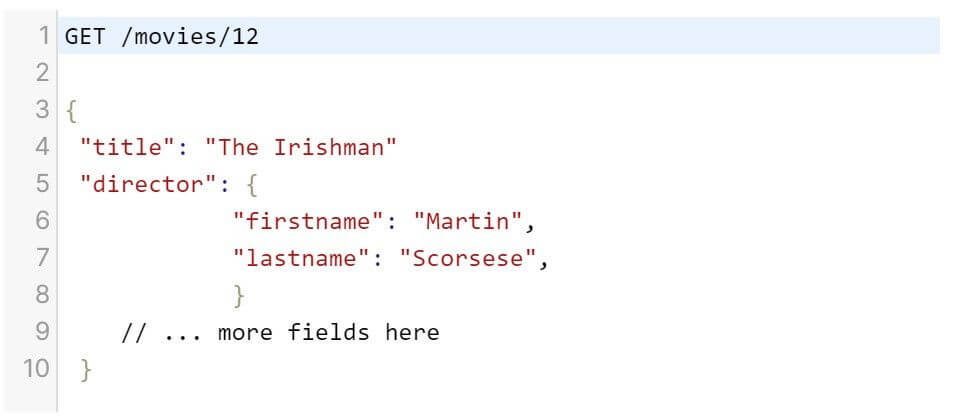
source: https://x-team.com/blog/rest-vs-graphql/
In GraphQL, we can define a schema with that field and build a query that returns just only the data that we want.
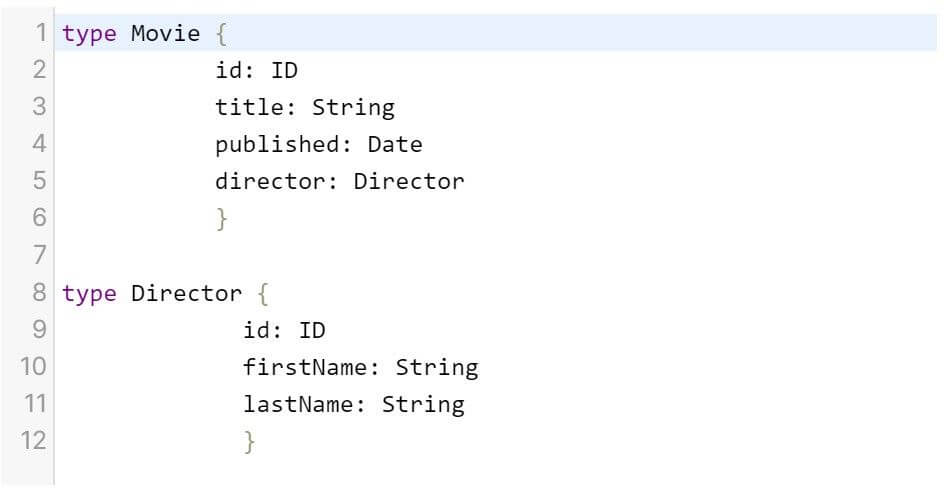
source: https://x-team.com/blog/rest-vs-graphql/

source: https://x-team.com/blog/rest-vs-graphql/
About versioning, we don’t care about it. With Graphql we can create new fields to the API, and our clients don’t break.
Caching
GraphQL doesn’t follow the HTTP spec for web cache in the browser, by our nature just only endpoint.
3rd party
Exposing the API to the 3rd party client could be dangerous. In Graphql we do not fully control how the client is using the data and we most care about joins in the schema that can bring a poor performance.
The Elasticsearch case
Could be hard mapping the complex queries of elasticsearch to the graphql model.
Graphql should be used in systems with a lot of domain objects like eCommerce.
REST analytics APIs with few relationships between entities.
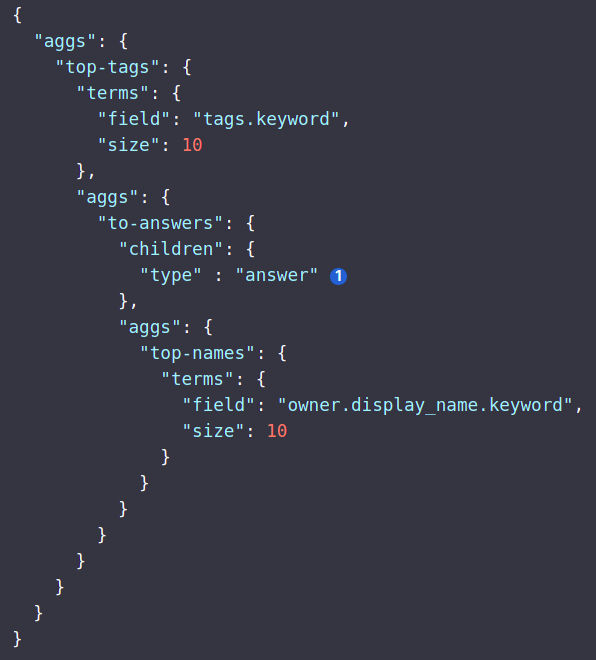
source: https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-children-aggregation.html
Backends For Frontends (BFF)
The BFF is a pattern that is connected with GraphQL for the purpose to bring autonomy to the client. When we have only one endpoint for general purpose. However, this does not exclude the one over another, instead could be supplementary.
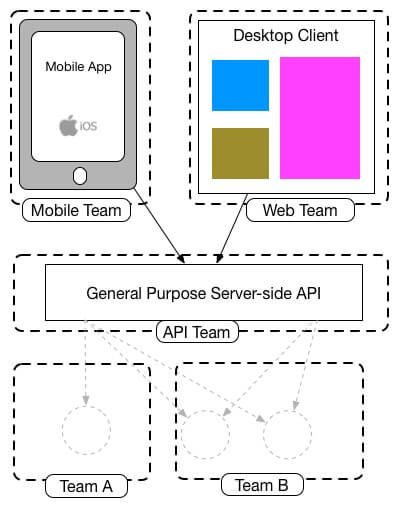
source: https://samnewman.io/patterns/architectural/bff/
So, when we apply this pattern we want to improve the experience of our clients’ applications to provide for them autonomy.
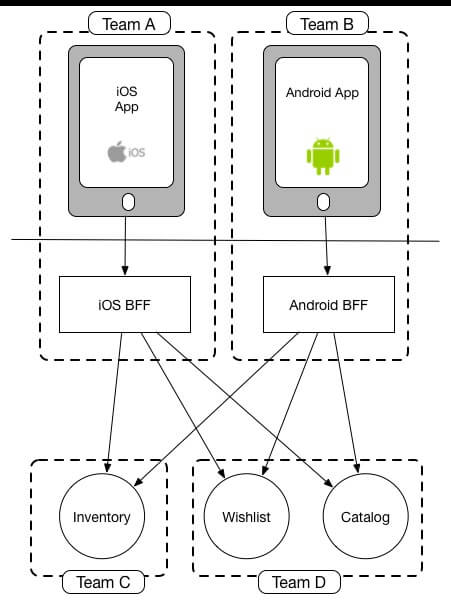
source: https://samnewman.io/patterns/architectural/bff/
Summary
GraphQL is a nice tool for the client-side because it provides just only an endpoint to all operations and one more to implement the subscriptions if you desire real-time changes on the client. It’s easy for the client to ask for only what they want and another interesting thing is the favor for the design API first. What we need to care about is performance. The facility with the client could generate inefficient queries. The nature of one only endpoint we do not have the web cache on the browser like a GEt operation on the REST API.
Bibliography
https://www.apollographql.com/docs/tutorial/introduction/
https://x-team.com/blog/rest-vs-graphql/
https://samnewman.io/patterns/architectural/bff/
https://www.thoughtworks.com/insights/blog/bff-soundcloud
https://www.toptal.com/api-development/graphql-vs-rest-tutorial
https://cdn.rea-group.com/blog/improving-graphql-performance-in-a-high-traffic-website/