Elasticsearch Understanding The Basic
The Elasticsearch
Today we talk about a search engine called Elasticsearch. There is another engine to it, but maybe not so popular. Elasticsearch is easy to manipulate your data to offer a REST API to interact with our data. Elasticsearch is a database of the family of Documents, so normally the database of this characteristic is something like that:
Abstraction: key-value store, where the value is a document.
To we remember how is a key-value store it seems like that:
Abstraction: hash table
Where the hash table stores a key-value on an index based on the application of the hash function to determine it.
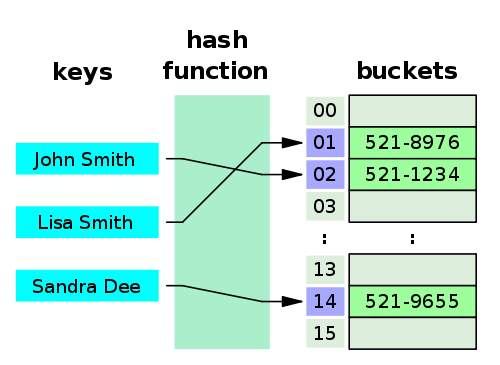
source: https://commons.wikimedia.org/wiki/File:Hash_table_3_1_1_0_1_0_0_SP.svg
And a hash table is a very performative data structure on search, insertion, and deletion with an average of O(1) on Big O.
In resume, elasticsearch is very used on search engine problems because internally it is using a hash table to store and find out the elements. Most specifically they use an inverted index. Inverted index stores what documents the term is it.
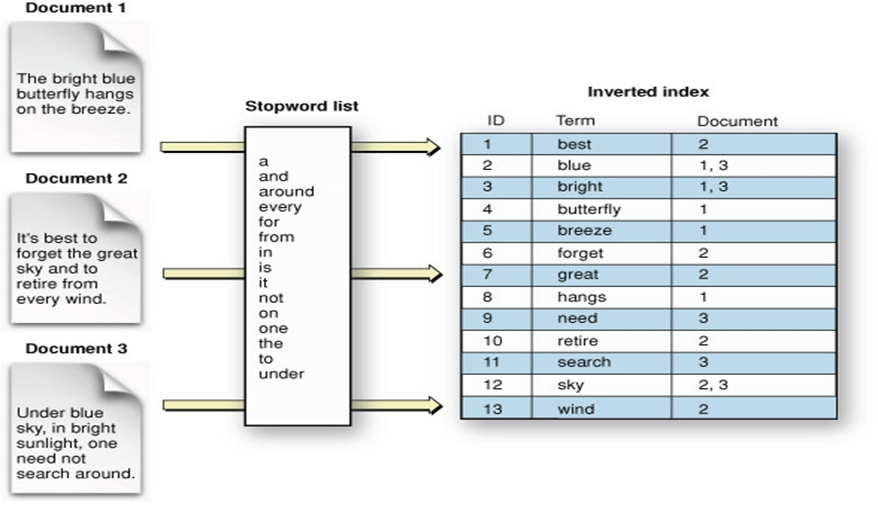
source: https://stackoverflow.com/questions/47003336/elasticsearch-index-sharding-explanation
Of course, Elasticsearch uses other data structures, but understanding the inverted index is important to the full-text search.
An important insight is when searching on the term with your prefix we have a O(log n) and an arbitrary substring is O(n).
The SQL Database Search
We can choose the SQL database to implement your search engine, but we should have in mind that the performance is not good like a NoSQL database, so go to the analysis.
Normally, we have a Linear time on a SQL Database when we execute a query like that:
SELECT product_id FROM productIn the example above let’s consider that the column product_id is not indexed, so how many your table size increases the time to perform the query grows linearly. Then, we have O(n) and in the best case if we are lucky to find the element in the first row on the table O(1).
Of course that we can improve the execution time of this query, creating an index to the column product_id, so the complex time decreases to O(log n), most relational databases use a B-trees to implement the indexes.
Remember that this consumes memory to store the tree.
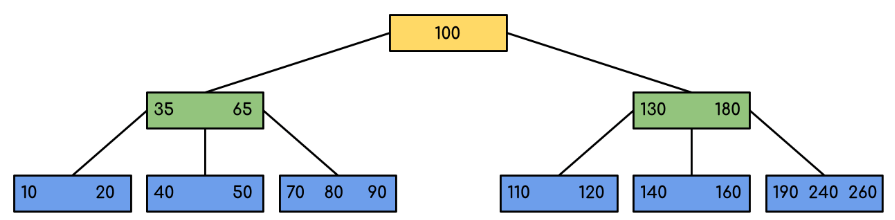
source: https://www.geeksforgeeks.org/introduction-of-b-tree-2/
Another example is with a WHERE clause like that:
SELECT product_id FROM product WHERE product_id=?It can appear that is a constant time O(1), but the database must execute a validation to every row to find the exact value that we passed to the query, it’s true if the first comparison is the value wanted, but in the average is executed a full scan on the table, so O(n), if you do not have an index.
With this concept in mind, we can see the power of the elasticsearch front of the relational database to the search use case. Below is the graphical comparison of the Big O scale.
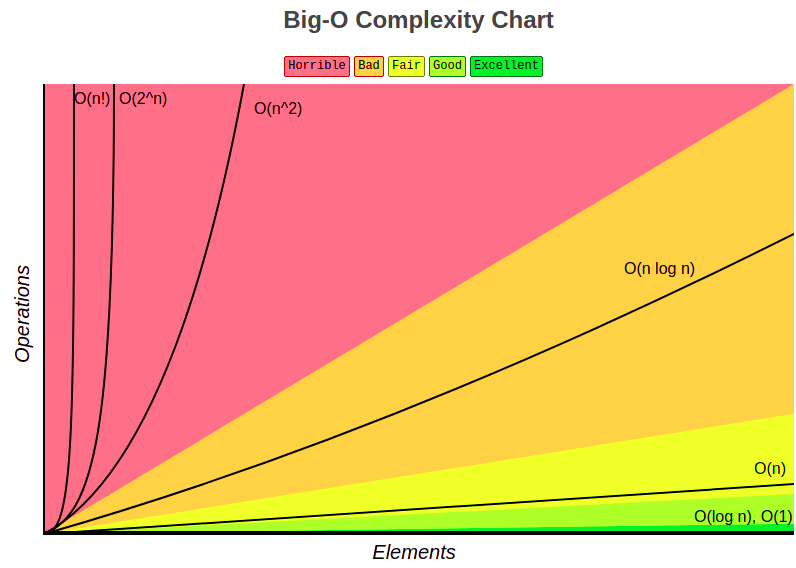
source: https://www.bigocheatsheet.com/
Remembering that the Big O notation is an approximation, the target is to see how the time increases based on the size of the input. To be very precise we should get into the bare metal, and understand the assembly operations and how the register interacts with the operating system to compute the real mensuration.
The Architecture
Elasticsearch is a distributed database, so we can scale-out, adding more nodes to your cluster to increase the throughput when a load of applications is boosting.
It is made use of the index where is the documents are logically separated of another type of documents on the database, for instance, we want to store two domains in your database, for instance, product and customer, to distinguish one of another we will create two indexes, an index called product to store the products documents and a customer index to store the customer’s documents, but an index is a logical separation it does exist physically.
An index is a logical name to access shards where the data is stored, but shards are like a bucket where the documents are stored after Elasticsearch applies a hash function to discover where the document is stored like a hash table.
Shards could be primary or secondary, where the writer is on the primary and the secondary is to read, by default, Elasticsearch creates one shard per index, but it can be changed. Another great feature is the possibility to replicate the data across the shards to improve redundancy and fault tolerance whether one node goes down.
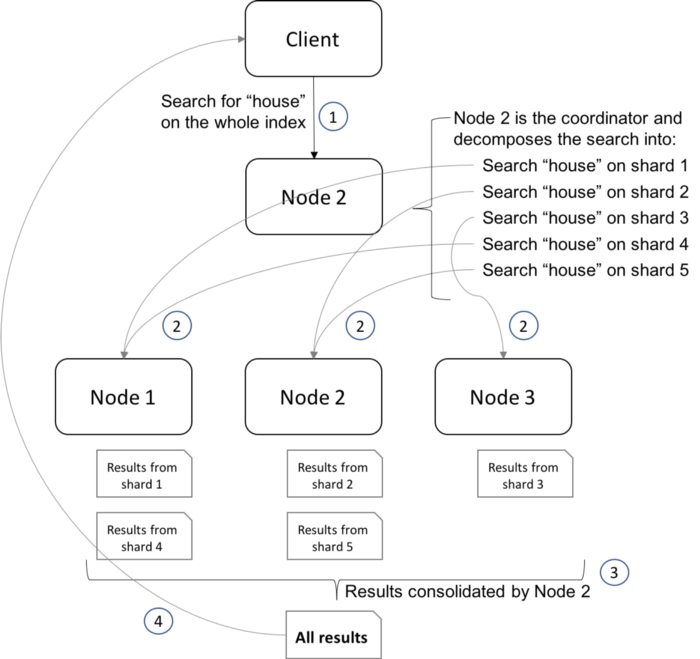
source: https://medium.com/hipages-engineering/scaling-elasticsearch-b63fa400ee9e
The picture above shows for us how a search works on Elasticsearch, with index, node, shards, and segments that do not appear on it, but it’s a below level of abstraction.
Deep into the architecture, we should understand another tool called Apache Lucene is a search engine behind the elasticsearch, what we know how shards to him is an index. In the Lucene index, we have the segments where is the fact the data is stored physically, a segment is a space of a defined quantify of bytes do store the data, these segments are smalls and continually there is a mechanism that compact the small segments to another bigger to improve the space utilization and the performance to search data.
The segments are immutable structures, which means that it is not possible to change them.
On Elasticsearch the update operation does not exist, when we want to update a document, what happens is a deletion forward by insertion of the document. Internally the documents to update are marked for deletion when we do the flush operation from buffer to disk, and smaller segments are merged into another bigger than it.
Apache Lucene has many things to learn, for now, it is enough to understand your applicability on the elasticsearch.
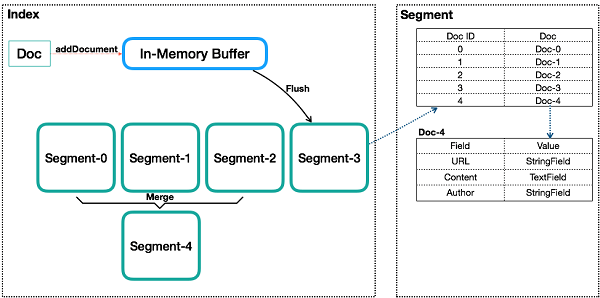
source: https://medium.com/hipages-engineering/scaling-elasticsearch-b63fa400ee9e
Summary
Elasticsearch is a nice tool to search problems where our data increases and we need scale separated from another part of our ecosystem application. And it is easy to use, to provide a REST API, and a graphical interface with Kibana. Elasticsearch has other use cases like store logs, machine learning to predict things over the data, and geospatial search.
Bibliography
https://stackoverflow.com/questions/4694574/database-indexes-and-their-big-o-notation
https://www.kdnuggets.com/2017/08/write-better-sql-queries-definitive-guide-part-2.html/2
https://en.wikipedia.org/wiki/Hash_table
https://www.bigocheatsheet.com/
https://rob.conery.io/2019/03/25/wtf-is-big-o-notation/
https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
https://alibaba-cloud.medium.com/analysis-of-lucene-basic-concepts-5ff5d8b90a53
https://qbox.io/blog/maximize-guide-elasticsearch-indexing-performance-part-2/